



Categories: BigData
Article Overview
Talend is a well-known software company (based in France) which sells a suite of tools for processing enterprise data, including
- server components for moving and transforming data
- a graphical IDE for defining data transformations
Exactly what the suite covers is explained later in section “Talend Components and Features”.
Unfortunately, their documentation is rubbish. Truly rubbish, some of the worst I have ever seen. Their website contains nothing except marketing; it is even hard to find out exactly what they sell. How to use the products at the “click, drag and drop” level is moderately well documented, but how things fit together at the architectural level is also badly lacking.
After much effort, I have scratched together an approximate list of features and products, and some detail that is relevant for designing an architecture that includes Talend components. Corrections and contributions to this article are welcome; much of the following content is just guesswork.
I am a software architect and developer, and occasional sysadmin, and am viewing Talend at that level, looking at:
- how does it fit into the “big picture” of data flowing through a large organisation (architecture)
- how do developers interact with it to get work done
- how does code move from development through to production (in a controlled way)
- how can the system be installed
- how can the system be secured
By the way, starting in 2018 Talend have made an effort to move their product “to the cloud”, ie allow customers to buy “subscriptions” to a software-as-a-service hosted and managed Talend environment. This article is instead focused on the traditional on-premise-installation environment.
My Opinion of Talend
I’m personally not particularly enthusiastic about Talend’s software. I find it clumsy, inflexible, and inelegant. As noted, the documentation is also extremely poor.
I also hate graphical programming environments (ie programming via drag-and-drop) - the clicky/clicky drives me mad. Worse is the lack of proper version-control, code-reviews, unit testing, code-search, complexity metrics, code reuse, and much else. When something goes wrong, it can be very difficult to know what you did incorrectly. Even when just doing the Talend tutorials, I often got very weird error messages that took a long time to track down - sometimes I just deleted the problem components, and recreated them to make the error go away.
Implementing scalable/performant code is a real problem in Talend - you just don’t have the control. Similarly, implementing properly robust code with proper error messages just cannot be done.
On the other hand, if I had to create a dozen simple ETL-style workflows without any supporting framework at all, it would be necessary to recreate a lot of features that Talend already has (logging, buildservers, etc). Documentation would of course also be necessary. Despite the limitations in Talend’s core ETL-based functionality, I’m not sure that a roll-my-own solution would actually be stabler, cheaper or faster than licensing and installing Talend and training the relevant staff on its use.
If the requirements included more advanced features such as master-data-management (Talend MDM), or moderately complex data-cleanup tasks (Talend DataPrep), then Talend could well be less painful than a custom solution.
Of course Talend isn’t the only option; it has lots of competitors. Are any of the alternatives better? Well, I don’t have sufficient experience with competing products to say for sure. All I can say is that there is plenty of room for improvement..
Talend and Open Source
Before we look at Talend, I just wanted to make a few comments about Talend’s relation to the Open Source principles. Talend claims in multiple places in its marketing materials that it provides “open source solutions”, or “based on open source”. In fact, source-code for several components of the Talend suite is available. Unfortunately, however, source-code for critical components necessary for serious use of the suite are not - in particular, the TAC (Talend Administration Center) is proprietary. There also appears to be no effort to make the code easy to find or easy to build, and as far as I can see there is no community around the open-source components. In practice, therefore, Talend’s open-source nature is of no practical use and the software should be treated like any other proprietary solution.
Talend does make it easy to download prebuilt binaries of what it calls community open-source editions of the Talend Studio developer IDE, and of the desktop-based variant of the Data Preparation tool. However each open-source IDE download is bundled with just a specific subset of the available “plugins”, meaning that if you wish to work with two different featuresets, you need to keep swapping IDEs; with a licensed version of Talend you receive a single IDE with all plugins. Most critically, integration of the IDE with version-control (so code can be shared between users) relies on the TAC - which is a proprietary component.
Based on the number of questions in StackOverflow, there does appear to be a moderate number of people using Talend’s “free downloads” - primarily in India. The quality of questions and answers in these forums is extremely low - ie basic user-level howto questions.
Talend’s code is based heavily on two open-source projects: Eclipse and Apache Karaf. Desktop applications (the Talend Open Studio IDEs and Data Preparation Free Desktop) are implemented as plugins for the Eclipse Rich Client Platform. When a component may run either as a client-side or server-side component (eg the talend job-compilation tools) then they are usually implemented as Eclipse plugins, and on the server-side are run as a “headless eclipse instance”. When the server-side component also needs a UI (eg the AMC logging user interface) then the server-side version uses the Eclipse Remote Application Platform (RAP) which replaces the standard GUI widgets with an html-generation layer. Note however that Talend’s internal toolset is not completely consistent; I suspect several components were originally developed by other companies before being bought and merged into the Talend suite.
Talend and Training
I have failed to find any books on the Talend suite of applications; it appears that no-one has published such a thing.
I have also failed to find any comprehensive external articles or tutorials. There are occasional articles on various specific topics, eg on Talend’s own community site but they fail to provide any big-picture or architectural-level info. The few useful sources I have found are listed at the end of this article under “References and Further Reading”.
Talend’s help site is better than nothing, but nevertheless it appears that the company has not invested much effort in this site. The help-site’s architecture section is a start, but unfortunately far from complete.
Talend do have a set of for-pay “online training courses” which I have completed a couple of; they are well-done but (at least so far) there are only user-level courses available, ie how to use the Studio IDE. Lots of help on how to search for components, where to drag-and-drop, etc - but nothing on architectural concepts like high-availability or scaleability, or how to combine different components of the Talend Suite to form a complete solution for a use-case.
In summary, the company appears to make it extremely hard for anyone to actually design a solution involving their products. It therefore puzzles me why they have any customers at all - if you have created a Talend-based solution, please let me know (in the comments) how you actually discovered what Talend does, and how to apply it…
This article hopefully provides at least an overview of the available functionality and architecture which the official documentation is lacking.
Of course, such resources are “moving targets” - it may be that by the time you read this article, the above sources of information have improved. It would therefore be a good idea to check them in addition to this article.
Talend In The Cloud
As noted briefly in the overview, Talend is traditionally something that gets installed on-premise, but the company is currently making efforts to provide/sell a hosted software-as-a-service solution instead.
Personally, I’m skeptical that this will get any great customer-base. Many companies still host their data on-premise, in which case a cloud-based data integration/transformation solution makes little sense. Similarly, Talend’s ESB (application integration) tools make little sense when integrating applications that are running on-premise.
Even when company data is in the cloud, I find it hard to imagine that a hosted service at the level that Talend provides can be verified to properly secure the data that flows through it; setting up a secure on-premises Talend instance is complicated enough. Similarly, diagnosing problems would seems to be an extremely difficult problem in such a hosted solution. Note that I am not against cloud-based solutions (I develop them for a living); however given Talend’s inherent complexity (and frankly, bugginess) I think it is a difficult area to tackle.
In any case, this article is primarily about an on-premise solution, not a cloud-based one.
Terminology
The words “job” and “dataflow” are approximately the same thing - an executable application. The word “job” was appropriate in the early days of Talend where the “standard data integration” featureset was the only one available; code running in “batch” mode can be called a job. Newer features such as code running in an ESB to handle SOAP requests, or real-time-streaming, is not “job-like”. The term “dataflow” is therefore now generally preferred.
Talend Features
The following list describes the core features that the Talend suite offers, and the physical components that provide these features. These featuresets are examined in more detail in the section “Talend Usecases”.
Weirdly, the Talend website makes it almost impossible to get this information - details of products are scattered across multiple pages, and functional details are mixed with licensing information in an almost incomprehensible manner. And every page includes multiple suggestions to “contact our sales department”. Possibly this confusion is a deliberate plan to draw potential customers into direct communication, but it is very annoying.
Features:
- (Standard) Data Integration (the oldest part of Talend, ie the original featureset on which the company was founded)
- A bunch of components in the Studio palette related to reading/writing/copying files, reading/writing databases, and transforming records
- A “code generator” within Studio which takes the “component graph” created by a developer and generates a Camel-based Java application from it
- Normally, resulting app runs in “batch” mode, eg once per day
- Application Integration (aka ESB Integration) (the next-oldest part of Talend after standard data integration)
- A bunch of components in the Studio palette related to receiving SOAP or REST requests and performing some associated logic
- A “code generator” within Studio which generates a Camel-based Java app (as with standard data integration) or an OSGi bundle
- Normally, resulting app runs long-term, serving requests from other applications
- Big Data Integration
- A bunch of components in the Studio palette related to reading records (from files or databases), transforming them, and writing them back to files or databases
- A “code generator” within Studio which takes the “component graph” and generates a MapReduce or Spark application from it
- Normally, resulting app runs in “batch” mode, eg once per day
- Realtime Big Data Integration
- A bunch of components in the Studio palette useful for defining “streaming processing”
- A “code generator” within Studio which takes the “component graph” and generates a Spark-streaming application from it
- Data Preparation
- Components in Studio palette
- Additional Studio “perspective”, and standalone interactive webserver which:
- Allows user to interactively ask questions like
- How many values in this column are null?
- Does this string-typed column actually contain only numbers (and if mostly numbers, what are the non-numeric values)?
- Does this numeric column contain any weird “outlier” values?
- Allows user to interactively “fix” a dataset
- Allows user to interactively ask questions like
- Big Data Preparation
- Enhancements to Data Preparation to work with hadoop
- Data Stewardship
- Components in Studio palette and standalone interactive webserver which provides “data governance” features (what datasets exist, what are their schemas, where did the data come from, etc)
- Provides “human workflow” support for organising/coordinating multiple manual steps related to data validation and governance
- Data Quality
- A bunch of predefined algorithms for scanning data for interesting patterns
- Useful for fraud detection, time correlation, and similar tasks
- Implemented as both studio-side code (limited scalability), and a standalone webserver (more scalable)
- Master Data Management
- Acts as a centralised repository of “master data”
- Wraps a relational database in which the data is stored
- Validates all data going into storage against “models” and “rules”
- Somehow useful for Governance and Stewardship
- Technically quite different to all other Talend tools (because the product was purchased from another company)
- Data Mapper - not sure what this is, but it appears on some diagrams
- Metadata Management
- Tools for tracking schemas associated with data. I’m not entirely clear on the details, but believe this “feature” is used by various components. See also
- “Dictionary Service” (see below)
- “Metadata Bridge” (propagates schemas from source systems or entity-relationship-modelling-tools into Talend Studio)
- Tools for tracking schemas associated with data. I’m not entirely clear on the details, but believe this “feature” is used by various components. See also
Talend Non-Functional Features
There are some additional “non-functional” features that are included in some licenses and not in others:
- High-availability support for execution servers (ie when execution server is down, job is deployed to alternative server)
- Automatic load balancing of jobs across execution servers
- Single-signon support aka IAM (only needed when running multiple webserver-based components like Data Stewardship + Data Preparation)
Talend Components
This section describes the physical components (installable packages of software) that Talend uses to implement the above features.
Typical Talend Architecture (standard data integration featureset with commercial licence):
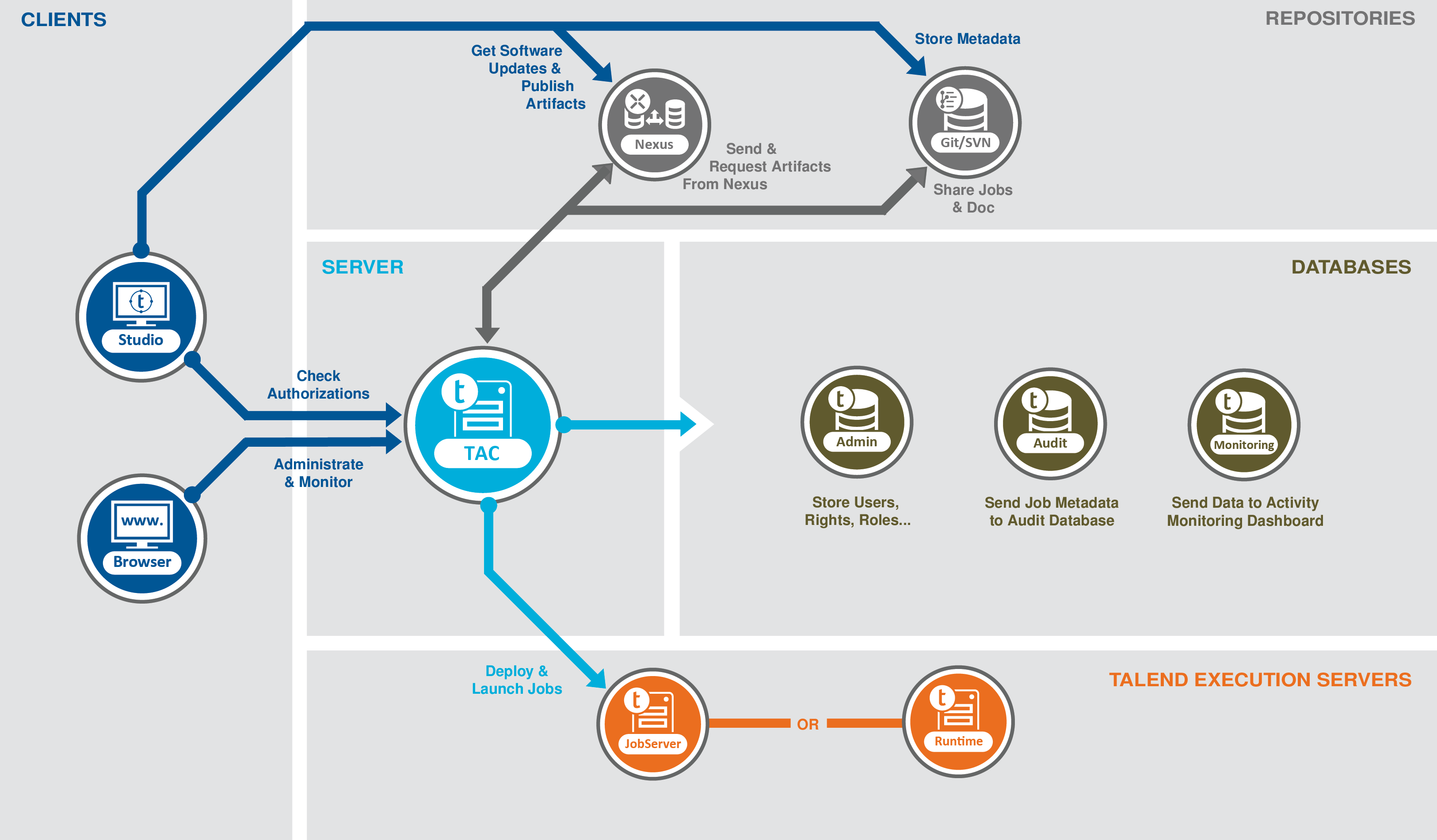
- Talend Administration Center (TAC)
- Manages user passwords and roles
- Coordinates use of the version control system between users
- Provides web UI for scheduling tasks on “execution servers”
- Provides a “build-server” for compiling code from version-control and deploying the output to the artifact repository
- Provides an interface for modifying various “config settings” stored in a relational DB and usde by other Talend components
- Artifact Repository
- A standard Nexus artifact repository for holding compiled jobs
- Version Control System
- A Subversion or Git instance (not provided by Talend) where code from Studio gets checked in
- AMC Logging
- A relational database schema into which statistics and status info from jobs is written
- A web-front-end for inspecting log-related information (accessible via the TAC)
- LogServer
- An ELK stack (elasticsearch, logstash, kibana) setup for similar purposes to AMC
- Execution Server tools
- A “jobserver daemon” that is installed on “worker nodes” so that the TAC (and Studio directly if allowed) can run jobs on that node
- A “runtime OSGi daemon” that is installed on “worker nodes” to run OSGi bundles generated from Studio and “deployed” via TAC (or Studio directly).
- Dictionary Service
- A “schema repository” (similar to HCatalog or Kafka Schema Repo) which can hold runtime schemas shared between “Data Preparation” and “Data Stewardship” servers.
There are also some non-free third-party software components that are bundled with some licenses:
- SAP RFC Server (“..acts as a gateway between Talend Studio and an SAP server. It receives IDoc documents from the SAP server and makes them available for processing in Talend Jobs”).
Note that “compiletime schemas” used in Studio are shared via the Studio repository
Talend Licences
As noted in the introduction, the “free/open-source” components of Talend are not very useful; to set up data processing using Talend (eg to provide ETL for a data warehouse or data lake), you will need to buy a license for the necessary components.
Weirdly, the Talend website makes it very difficult to actually find out what licenses are available, and what they include. After significant research, I believe that the following licensing information is correct; at least it should form a good basis for discussion with Talend’s sales staff.
Simple Licences
Talend (standard) Data Integration is probably the “most basic” licence. It provides:
- Talend Studio (ie eclipse IDE)
- A copy of the Nexus artifact repository (actually available for free download)
- Talend Administration Center, including AMC logging
- Talend Log Server (Elasticsearch/Kibana-based log storage and analysis)
- Talend Jobserver and Runtime daemons for deploying on worker nodes (these are also available for free download)
- The “standard data integration” featureset from above
Talend Application Integration (aka ESB) includes:
- Studio/nexus/tac/logserver/jobserver as with the standard bundle
- Plus the “application integration (ESB)” featureset from above
Talend Big Data Integration includes:
- Studio/nexus/tac/logserver/jobserver as with the standard bundle
- Plus the “big data integration” and “realtime big data integration” featuresets from above
Talend Cloud Integration (see more later) includes:
- Studio
- Extra Studio palette components that are related to cloud, eg copy-to-S3 or load-to-bigquery.
- Cloud-integrated versions of Data Preparation and Data Stewardship
Talend Data Quality (aka Data Quality Portal) includes:
- Studio
- Data Preparation + Data Stewardship featuresets
- Data Quality studio components + Data Quality webserver
- (probably TAC etc, but not sure)
Platform Licences
The following “platforms” provide bundles of functions and non-functional features:
- Data Management Platform = (Standard Data Integration) + (Data Quality) + high-availability and load-balancing
- Data Services Platform = (Standard Data Integration) + (Application Integration aka ESB) + (Data Quality)
- Big Data Platform = (Data Management Platform) + (Big Data) + (Big Data Quality)
- Realtime Big Data Platform = (Big Data Platform) + (Realtime Big Data)
- Master Data Management Platform = (Master data management featureset) + usual tools (Studio, TAC). Really belongs in the “simple licences” category, but has name “platform”.
Data Fabric License
This appears to be an “all of the above” license. The term “data fabric” is also used to describe the full set of Talend features in an architectural sense.
Free Products
Talend insists on calling these “open source products”, but I don’t really believe they qualify - at least in spirit. Source is hard to find, and building these things appears completely undocumented. Talend does apparently contribute source-code back to the open projects on which it builds (Camel, etc). However the higher-level tools are really just “free to use” rather than “free to modify”, as modifying them appears practically impossible. Features critical for real production use are also missing.
The available downloads are:
- Open Studio for Data Integration - the Standard Data Integration featureset
- Open Studio for Big Data - the Big Data (and maybe Realtime Big Data) featureset
- Open Studio for Data Quality - the Studio components of the “data quality” featureset, but not the webserver.
- Open Studio for ESB - the Application Integration (aka ESB) featureset
- Open Studio for MDM - not sure whether the MDM server is included; I presume so as MDM would probably be useless without it
- Data Preparation free desktop edition - the Studio components of the “data preparation” featureset. Allows data exploration within the IDE, but does not scale to larger datasets like the server-based implementation does.
In addition, the “runtime server” for executing jobs (aka dataflows) on “worker nodes” is available for free. However the TAC which usually schedules execution of code on those nodes is not available (you could probably use cron manually, or similar).
Notes
I am not sure which licenses include the “single signon” non-functional feature.
Talend Core Component Overview
Before continuing with a description of the “use cases” to which Talend can be applied, it may be helpful to first look briefly at two critical components of Talend:
- the Studio IDE
- the Talend Administration Center (TAC)
Talend Studio
When you buy a Talend licence of any sort, you get one Studio instance (ie Eclipse IDE) with all the features you licenced.
When you download “free” products from the Talend site, each product comes as a separate Studio instance with just the features in that “free” product. As example, if you want to combine big-data and non-big-data components, then you’ll need to keep switching between Studio instances. And SVN integration comes only via the TAC, so have fun sharing code between developers…
Studio primarily provides a “drag and drop” approach to programming.
The original “data integration” feature is really just a GUI on top of Apache Camel - each “component” available for use in the graphical designer is a Camel component, and the wiring/config is simply camel routes and config. When a job is “compiled”, the result is a Java application that is based on the Camel framework.
The “big data integration” feature is not primarily camel-based; instead it converts the full set of components on the graphical designer into a MapReduce or Spark program. AFAIK, it then wraps this in a single-node camel-based program which is only responsible for submitting the MapReduce or Spark application to YARN.
The available set of components is different between “standard data integration” and “big data integration” jobs. Some of them have identical names (and similar purposes) but they are not the same components. The set of components available for big-data jobs is far smaller (limited) than for standard jobs, as only components which can be mapped to operations within a Spark or MapReduce program can be supported.
Once implemented, a job can be:
- Executed directly from Studio
- Exported as an executable application and run directly
- Exported as an executable application and sent to a “jobserver” execution server for execution
- Exported as an OSGi module and sent to a “runtime” execution server for execution
- Checked in to SVN, and “deployed” via a TAC instance, which builds an executable or OSGi bundle and uploads it into Nexus, then deploys the Nexus artifact to an execution server
Studio offers reasonable debugging features when developing “jobs” - as long as the job is of type “standard data integration”. For “big data integration”, those features no longer work as the logic is executed in a cluster rather than locally.
Studio also has some features for “master data management” and “data quality” if you have licenced those features from Talend. These are quite separate from the job-design features.
Studio has a reasonably nice mechanism for sharing configuration settings between jobs: the “repository”. When a TAC is available, then data in the “repository” is shared across all developers. When no TAC is available, then those settings are only shared between jobs in the same Studio instance (local).
When designing a “standard data integration” job, components are connected together by “routes” which are buffers of messages which have an associated schema. One of the most important features Studio provides when designing jobs is tracking of the schema associated with each buffer. Schemas can be defined “abstract”, or associated with a specific file or database-table. Each component has an “input schema” which is the schema linked to the upstream component; the “output schema” might be the same, or might be different. An “initial” component which starts a job must explicitly specify a schema.
Components can also be connected together by “triggers” which are not a message-buffer, and do not have an associated schema.
Talend Administration Center (TAC)
This proprietary component is a webserver and API server that runs in the background, providing:
- Integration with SVN or Git for version control (sort of)
- A build system for compiling code from version-control and uploading resulting artifact to Nexus (maven-based)
- AMC logging system (allows viewing of system state, drilling into logfiles, setting up alerting on system problems)
- The ability to deploy tasks to an execution-server via a web interface (immediately, or when trigger occurs), where the code is an explicitly-provided zipfile or a maven artifact
- User management, ie users/credentials/rights for anyone using the TAC directly or via Studio.
Deployment/execution of a task can be triggered repeatedly on cron-schedule, or triggered when a specific file appears on a filesystem mounted on the TAC server. Tasks can also be triggered by other tasks, eg “when X completes successfully, run Y”. In a commercial environment, the TAC is really necessary to ensure clean deployment of code into production environments. The TAC stores internal data in a relational database instance (eg MySql) - something invisible to users.
It is possible to use other components of Talend without the TAC, but difficult. The Studio can still be used to implement workflows and compile them - but sharing code with other developers is difficult (that is normally coordinated via the TAC). Once jobs are created, they can be manually executed on the developer’s machine on which they were implemented - but that is obviously not useful for production use. Jobs can be manually copied to an “execution server” and then tools like cron can be used to trigger their execution - but that is all a fairly manual process. Alternatively, you could develop your own deployment and scheduling tools. In a licensed Talend environment, the TAC handles all these tasks - and more.
See later for more information on the TAC.
Talend Use-cases
Data Integration
A common problem within companies is the need to move data from one storage location to another, and apply some transformations on the way. The data source or destination is typically either a file or a relational database. The “Data Integration” components of Talend are intended to address this use-case.
Defining and managing data-integration logic in Talend is, frankly, ugly, clumsy and painful. However you have to keep in mind that such “integration” logic is usually ugly, ad-hoc stuff. And you have to keep in mind how this used to be done (and is still done in many companies) - batchscripts that execute old cobol programs, triggered from a windows service scheduler on a server everyone has long forgotten. In addition, “rock star” programmers aren’t interested in doing this stuff, so the tool needs to be useable by staff with little formal IT background. And in the end, “good enough, cheap enough, fast enough” is usually the company goal.
ESB
This featureset is mainly focused on usecases like “partner companies send us purchase orders”.
Using ftp or file-transfer (old-school integration) to start order-processing has many drawbacks; exposing a SOAP or REST service that partners can use is far more elegant.
The Talend Studio can be used to build a synchronous “service” via drag-and-drop (with the appropriate components). The result can then be exported as either a standalone Java application, or as a module that can be loaded into a suitable runtime. In either case, the resulting service runs long-term, responding to incoming requests - unlike the “Data Integration” use-case, where a job designed in the Studio runs periodically (time-based or trigger-based) in batch-like manner.
The “standalone” ESB service simply bundles Karaf in the generated jar.
Export as module is available in various flavours - eg for running in Apache Camel, or in JBoss ESB.
Data Preparation
When some third-party (whether external company or internal department) provides a set of data to be analysed, it is often necessary to first “explore” the data, finding out what info is present, what format it is in, and whether there are “weird values” present that might distort analysis results. It may also be necessary to “clean” the data (eg replace nulls in a column with a default value, or “clip” extreme values). The Data Preparation features of Talend can help with this task.
Data Preparation is an interactive process; it is not intended to be used when importing data regularly (eg ETL processes importing data daily into a data warehouse).
Master Data Management
In a large company, data falls into two categories:
- data managed by the department that collects it
- centralised data shared by all departments - ie “standardised” data
Master Data Management (MDM) is the process of handling “centralised” data. The data itself is stored in an underlying database, but there are additional tasks that “master data management” needs to perform, including:
- maintaining a proper description of all the tables and fields (more than just a relational schema)
- versioning table schemas - ie tracking changes to tables over time
- versioning table data - ie tracking changes to the contents of tables over time
- keeping change history - who changed master data, and when (for auditing purposes)
- publishing new versions of tables to consumers
Normally the amount of data managed in a Master Data Management system is relatively small - MDM maintains reference data, not things like invoices. Often the largest dataset managed in MDM is the “company product catalog”.
As noted elsewhere, the Master Data Management component of the Talend Suite is technically quite separate from the primary tools. It was in fact a product from a separate company which was purchased by Talend, and thus runs in its own server (though the Talend Studio IDE can be used to interact with MDM).
Data Stewardship
Stewardship is about maintaining good metadata on the various tables stored in a data warehouse or data lake. Having ETL processes that take data from dozens of upstream systems and store them into a central data lake is not much use if nobody knows what data is in the data lake, or for a specific table:
- who authorized it to be imported
- how long may the data be kept
- how secret the data is (may it be provided to external parties or not)?
- etc
Data Stewardship and Data Governance are strongly related - Governance is about setting general rules regarding data, while Stewardship is actually applying those rules.
Other
The “big data” support in Talend supports the same “data integration” or “data preparation” use-cases described above - except on larger amounts of data than those typically deal with, or simply applied to data that is in a “scaleable” databank rather than a traditional one.
More on Eclipse and Karaf
Because Talend uses Eclipse so heavily, it may be worth briefly mentioning what Eclipse actually is.
At the core of Eclipse is an OSGi container - a small framework that allows Java jarfiles (modules) to find and call “services” in other jarfiles. Eclipse then provides hundreds of modules that provide different functionality. Anyone can write their own modules to provide custom logic, then combine these with the appropriate “standard” modules to produce interesting applications.
The Eclipse IDE is simply that OSGi container with a set of modules that provide graphics, menus, dialogs, and code-editors.
The Talend Studio is very similar to the Eclipse IDE that a Java developer might use, but with a few modules left out (eg the Java sourcecode editor) and a few custom modules added (eg the drag-and-drop component editor).
Some Eclipse core modules define interfaces for interacting with a user - menus, dialogs, etc. The default implementation of these interfaces uses the SWT graphical library to draw on a screen. However a third-party project (RAP) has created alternate implementations of these interfaces which generate HTML and Javascript; this allows an eclipse instance to run as a remote “webserver” while the remaining application code works (mostly) unchanged. The result isn’t perfect, but Talend does occasionally use this approach for some components (eg the AMC log viewer) rather than implementing a “proper” HTML interface.
Talend does provide some Eclipse modules which provide a “network API”, without any user interface. These can then be installed in a client-side Studio instance - and the same code can be run server-side by starting a “headless eclipse” environment. Given that “headless eclipse” can be just the core OSGi framework plus required supporting modules, this is not in itself a poor design. However in practice, Talend bundles the entire Eclipse Rich Client modules in their “eclipse-based servers” thus wasting disk-space and memory.
Apache Karaf is also an OSGi container with a set of associated optional modules - but it is aimed at server-side usecases while Eclipse is aimed at client-side usecases.
Apache Camel builds on top of Karaf with a set of modules for routing data and reacting to requests. Camel is intended for moving data around within a company; it calls itself an “Enterprise Integration Platform” and is similar to an “Enterprise Service Bus”. Talend Studio workflows compile to OSGi modules which depend on Camel modules.
Execution Servers
Overview
When a job is “published” from Talend Studio, either “jobserver” or “runtime server” format is selected. The job must then be deployed to the corresponding execution environment.
Selecting “jobserver” produces a zipfile containing the Camel framework, a bunch of camel components, camel configuration files, and a shellscript to launch it all. In short, each “component” specified in Talend Studio is mapped to a Camel component, and the “wiring” between them defines the camel routing configuration. Note that many of these camel components are Talend-proprietary. The zipfile is completely self- contained, and can be executed directly if desired.
Selecting “runtime server” produces an OSGi bundle (a jarfile with special metadata). As far as I know, this is also camel-based, ie the OSGi bundle includes camel routing info and other config. I suspect that the Talend-specific dependencies are not included in the generated bundle as they are provided by the execution server.
Jobserver Execution Server
The Talend Jobserver is an extremely simple application that needs to be set up as a daemon service on one or more “worker nodes” (VMs). The application opens a network port and waits for “jobs” (zipfiles) to be sent to it. For each job, it unpacks the zipfile and writes the contents to disk, then spawns a new process which executes a shellscript provided within the zipfile. In the case of a “talend batch job”, that shellscript will start a Java VM, run the logic that was originally defined via Talend Studio, then terminate.
In the case of an “ESB Service”, the shellscript starts a Java VM which then listens for incoming REST/SOAP requests until terminated.
The Talend TAC can then be used to “deploy” any application (“job”) to a jobserver instance. The file to deploy is taken from the Nexus artifact repository (thus ensuring “clean repeatable” deploys in a prod environment).
Talend Studio can also send jobs directly to a jobserver instance, if firewall and security settings allow. This allows developers to test larger jobs than will run on their laptops. It also allows cheapskate companies to do basic ETL processing with the free Talend downloads. The TAC “cron-like” scheduling can even be emulated by just using cron directly on the VM hosting the jobserver instance. Ecch.
Runtime Execution Server
This is a customised OSGi environment. On startup, it opens a port and listens for “jobs” to be sent to it. As far as I know, a “job” is simply a reference to an artifact in Nexus which gets downloaded and deployed into the OSGi instance.
Note the difference between jobserver and runtime approaches: jobserver creates a new unix process for each “job” (which is usually a Java VM) while the OSGi environment deploys jobs into an existing process.
JBoss ESB Server
When building an “ESB” service with Talend, the code can also be exported as a module that can be loaded into a JBoss ESB server.
Other Execution Server Topics
When Talend is used to define many ESB services, then obviously the OSGi approach is better (spawning one long-running process per service is not efficient). For “batch mode” applications, the “jobserver” approach is probably stabler (out-of-memory will not bring down unrelated jobs). A Talend environment will likely have multiple execution server instances (VMs). High-availability and load-balancing of jobs across the pool of available execution servers is an “add-on” feature that is included in some Talend licenses but not others - ie even if you have a TAC license, you might not have failover or load-balancing. In any case, I suspect the load-balancing is fairly primitive and not anything like YARN.
Data integration tasks often read files - and therefore the filesystems that a job requires must be mounted on all execution-server hosts which might run the job.
Big Data Workloads
Talend Studio can be used to define a “big data workflow”, using components from the “big data” set. Compiling the workflow results in a standalone executable or deployable module which is a “spark driver” application. This application runs on a Talend “execution server”; when started the application communicates with a YARN cluster to allocate Spark worker nodes and then execute a spark program on those nodes. The set of available components for such workflows is limited, ie only a small subset of Spark functionality is supported.
I am not currently sure how a Spark Streaming (aka “realtime big data”) workflow gets executed.
Version Control
Talend Studio can communicate directly with a Subversion or Git server. However it isn’t normal version control:
- Each time a developer clicks “save”, a commit is automatically made - with an auto-generated commit message
- Studio periodically polls the server, and automatically updates the local files to the latest available versions - ie auto-update
Diffs are therefore mostly useless, as is the history. A single branch is simply used to share files between all users attached to the same branch.
As far as I can tell, job development works on a “locking” model, ie a user “locks” a job when they start working on it, and must explicitly “unlock” the job before any other developer can work on the same code - even when using a distributed version control system.
Branches are somewhat useful - there are options in Studio to “deploy a version”, in which case a new branch is automatically made in the version-control-system.There is a basic graphical-diff-tool that can compare branches - though the output is not very readable.
The Talend downloads (including licensed ones) do not include Subversion or Git - you need to set up your own instance.
Unit Testing
All traditional programming languages (Java, Python, etc) have well-established frameworks for implementing unit-tests, ie writing code that verifies that the application is performing as expected.
However graphical programming environments typically have very limited support for unit-testing, and Talend is no exception. A workflow can be configured to accept “mock data” as input, run the workflow on it, then verify that the output exactly matches a set of expected results. Achieving even this limited form of testing requires using variables in many places in a workflow rather than constants, in order to be able to handle the mock data correctly. See Talend’s documentation for more details.
Logging, Monitoring and Debugging
A workflow can be run in Talend Studio directly; the workflow is “compiled” to a Java standalone application, then executed locally on the user’s desktop/laptop. A workflow is always given a (host, port) pair to report running statistics to, and when run locally the Studio that launched the workflow receives this data and can display it interactively on top of the graphical workflow representation.
A workflow can also be sent from Talend Studio to a remote Execution Server. The developer’s system obviously needs to be able to connect to that (host, port); less obviously that target execution-server needs to be able to connect back to the Talend Studio instance to report statistic info. That reverse connection can be a problem in some corporate environments.
A workflow can be configured with database connection data and credentials for the AMC database tables. It will then write startup/shutdown/error messages directly into that database, and that information can be viewed via Talend Studio (by entering the same DB connection and credentials), or via the TAC web interface. The database host must of course be accessible from the relevant locations.
Components such as Execution Server “agents” also have text logfiles which can be collected by the Talend Logserver (ie Elastic stack) if it is set up appropriately. I am not sure whether individual workflows can write log messages intended for the Talend Logserver.
Overall, the logging/monitoring/debugging options are significantly more limited than with traditional programming languages.
Dev/Qa/Prod Environments
To set up a proper multi-phase development environment, each environment has its own TAC, version-control-system, and execution servers.
Ideally the nexus server is shared between environments. This makes it possible for a developer to check in code and deploy to development, which triggers creation of a corresponding artifact in Nexus. The QA instance of TAC can then simply take that same artifact when released, and deploy on QA execution servers. Once approved, the prod TAC can take the same artifact and deploy on prod execution servers.
Alternatively, each environment has its own nexus instance, and artifacts are replicated between nexus instances using some external process.
Variables used by jobs (filepaths, server addresses, etc) will differ between environments. As far as I can see, the usual practice is for the developer to define a “context” for each environment, and add the correct settings for each environment during the build process. When the TAC deploys a task, it then specifies which context to use.
Talend Cloud
Talend’s help site has reasonable documentation on the architecture of its cloud offering.
Deployment architecture:
- 5+N custom servers are deployed on VMs in some cloud environment (AWS, Azure, GCP, OpenStack, etc)
- A few on-premise components are also required
In-cloud components:
- Cloud Management Console (equivalent of local TAC)
- Integration Cloud - webserver that users interact with to
- Start predefined jobs created via Studio
- Interactively create new jobs (limited functionality)
- Upload/download files to/from cloud storage
- Cloud Data Preparation - cloud version of the “data preparation” featureset
- Heavy data processing is delegated to “cloud engines”
- Cloud Data Stewardship - cloud version of the “data stewardship” featureset
- Dictionary Service - a schema repository used by DataPrep and DataSteward
- A variable number of “Cloud Engine” VMs
- Used to execute standard jobs
- Used to execute tasks created by DataPrep
- Not currently clear if these are dynamically allocated, or are static VMs.
Local components:
- End-users just use web-browsers to interact with “cloud components”
- Developers still use Talend Studio
- Usually at least one “execution server” instance is installed on-premise (called “remote engine” for some reason in the talend cloud docs)
Studio includes extra components:
- tDatasetInput, tDatasetOutput, tDataprepRun ==> all for “cloud data preparation” feature
- Also components for “data stewardship”
It isn’t currently clear to me why a local execution server (aka “remote engine”) is required.
Scalability and High Availability
When using Talend without a license, jobs are developed in Studio and exported as standalone executables. It is the developer’s responsibility to then get these applications executed somewhere and somehow.
When using Talend with a license, then the TAC delegates each job to one of the fixed set of Execution Server instances. The overall capacity of a Talend environment can therefore be scaled by adding servers running an appropriate Execution Server agent (jobserver, runtime, or esb-runtime). A job may be scheduled on a specific execution server instance, or on a “virtual execution server”; a virtual execution server maps to a set of physical execution servers using basic load-balancing algorithms.
A single workflow is not distributed; it runs on a single node. A workflow can be made multi-threaded by using the appropriate Talend components when designing the workflow, but this is rather complex.
However a single workflow can launch a parallel Spark application in a Hadoop environment (ie on YARN). When running such a “Big Data” job, processing naturally scales according to the number of Spark worker nodes specified for the job.
Most Talend components can be set up for high availability, ie the system continues running when one or more hosts are not available. Configuration is rather complex though. You are responsible for many steps including:
- having a highly-available relational database for the TAC and AMC
- having a highly-available setup for the Nexus Artifact Repository
- having a highly-available source code control repository
Installing Talend On-premise
Installing the “free, open-source” components is trivial; they are client-side-only applications except for the “execution server”.
Installing a licensed, production-quality enterprise-scale Talend environment is extremely complex. In fact, don’t even try to do this on your own; you will need a consultant from Talend to get this done.
I have written a separate article on installing Talend but this only covers setting up an environment suitable for learning and prototyping.
Strengths and Weaknesses
In summary, Talend addresses several use-cases commonly encountered when doing data-processing within a company; doing ETL and providing basic ESB services.
A graphical approach to development has a few advantages, particularly if you have simple requirements and want to pay developers very little. The best feature of a graphical environment is that it looks good in demos. However it also has significant disadvantages.
Much of Talend’s architecture is very simple - they are doing nothing clever. However a pre-existing product is likely to get you going quicker than implementing something from scratch. And if you don’t have much in-house software experience then it might be a better option.
However I have a strong feeling that these use-cases can be better addressed than through the Talend solutions - and hope to find a better product in the near future.
Other Notes
Talend does not generate “distributed” applications; each “job” is a single blob of code that can only be scaled up by deploying it on a server with more ram and faster CPU.
There are some features that allow different components within a job to be executed by different threads within the same process.
A “big data job” runs as a single blob of code in one process - but its role is only to launch a MapReduce or Spark job in a YARN cluster, and therefore is not a scalability bottleneck.
Using “hadoop components” within a “standard data integration job” allows interaction between a traditional Talend job and a hadoop cluster, but not efficiently. When a component is used to execute a Hive query, and then another component is used to map or filter that data, the hive output is copied to the process where the Talend DI job is running, and mapped/filtered there - not within the cluster. Within a “big data integration” job, things are different - the read/map/filter will all be part of one MapReduce or Spark job; however the options available are far more limited and the debugging/logging features of Studio mostly do not work.
Normally a server-side “commandline server” instance is used to compile code into artifacts which are deployed into nexus. However as the code generated by Studio is a totally normal Maven+Java project, it can be compiled by any maven instance; this makes it possible to use an external build server (eg Jenkins) if desired.