



Categories: Architecture
Introduction
In a distributed system, how do different components get access to data that is needed by them, but not owned by them? At willhaben we do this by having data-owning components publish that data to Kafka compacted topics, and having components which need a “read only” copy of that data listen to those topics and store the data locally. Martin Fowler calls this Event Driven Architecture with Event-carried State Transfer (quite a mouthful!); we call this a (Distributed) Read Model.
This article discusses why we do this; part 2 includes the details of how it is done.
Disclaimer: the architecture described here is relatively new for us. We do have all of this implemented in some form, but not yet consistently everywhere.
Update: CodeOpinion has a great overview video on this topic.
The Problem Description
Willhaben (as a site) deals with reasonably large volumes of data and has a quite complex set of functionality which evolves rapidly (multiple releases per day).
Our software is therefore built as a “distributed system” — multiple applications cooperating to provide the single integrated system that users see. Our goal system architecture looks something like this:
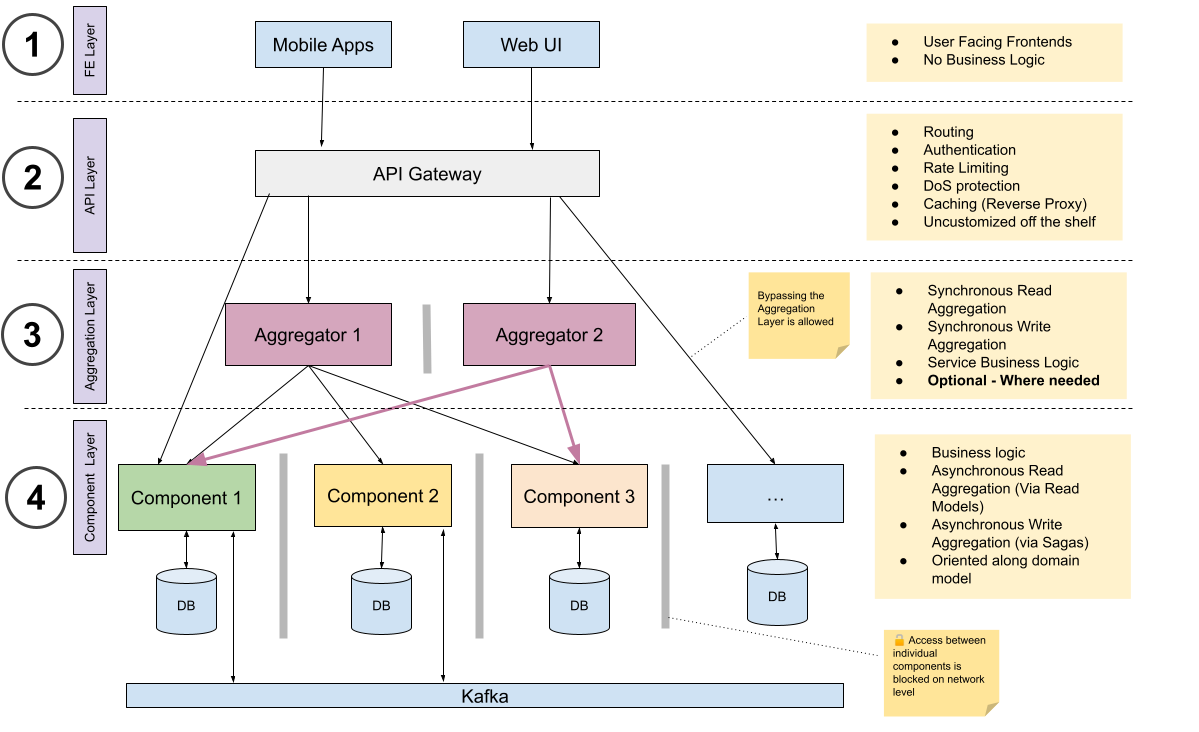
We use the term “aggregator” and “aggregation layer” where others might use the term “integration layer”1. It’s the same thing: a place for (small amounts of) code that interacts with multiple domains2. Note the lack of persistent storage in this layer! Note also that too much logic here leads in the direction of an Enterprise Service Bus and Service Oriented Architecture3 - approaches that have a few advantages and many disadvantages; in general we prefer to keep this layer optional and (where used) thin.
Each back-end (business tier) component corresponds to a DDD domain4, and has its own database. Each item of data is owned by one specific domain/component (the “source of truth”), and can only be modified by that domain. These could also be called microservices.
However components do sometimes need read-only access to data owned by other domains. It’s of course ideal to define bounded contexts in ways that avoid such shared data, but it isn’t always possible. In cases where data has one owner but multiple users there are basically three options:
- require all necessary data to be provided in each request
- make synchronous calls between back-end components
- replicate the data
The first option pushes the “cross-domain” integration up to the caller - a valid option sometimes, but not always applicable. The second is the obvious solution but has many many traps. We therefore prefer replication of data to synchronous calls; this article describes the benefits of this approach, how we do this, and what tradeoffs we made (because architecture always involves tradeoffs).
This technical design is also linked to our organisational approach (supports and is supported by it); see STOSA Architecture at willhaben.
Avoiding a Distributed Monolith
Monolithic applications are built around function-calls. However building a distributed application simply by turning some of those function-calls into remote-procedure-calls (in whatever technology) just doesn’t work — it ignores the 8 fallacies of distributed computing.
It is possible to build a distributed application around remote-procedure-calls (RPC) if they are appropriately designed and implemented, but it’s still very hard. And everyone involved needs to understand exactly what “appropriate” means. Unless great care is taken, the application will suffer many of the problems which are described below: hard-to-understand, compatibility problems, performance issues, complicated failure modes, etc. Trivial systems may not encounter many problems, but systems with many components, many transactions, and a lot of data, will be unstable unless these issues are addressed.
By following the data-replication principles presented here, it’s hard for developers to fall into these traps — no matter how much time pressure they are under. And, once the supporting infrastructure and patterns are present, we believe it doesn’t cost any more. In particular, we believe it costs less than doing an RPC-based system correctly (at the scale we develop software — not netflix, but also not trivial).
In fact, in order to avoid the dangers of a distributed monolith, we are attempting to build a system without any synchronous inter-component calls at all - see the diagram above in which direct network connectivity between components in the “component layer” is actively blocked. We acknowledge that is a departure from many other micro-service and event-driven architectures. However we propose that any API which by its nature requires synchronous coordination by multiple components generally indicates an incorrectly-partitioned system. In the few cases where such operations are really needed, we push that coordination up into the stateless aggregation layer. This doesn’t mean that core business logic should be duplicated; any business rule that is truly system-wide should be implemented in only one place. A component should use replicated data to make decisions only where those decisions are truly the responsibility of its bounded context. We may discover in the future that certain processes do require inter-component calls - but haven’t found any such cases so far.
Why Separate Databases
Each back-end component has its own database for multiple very good reasons:
- independent releases
- predictable performance
- security
When one component reaches into another component’s database to read data, then this impacts the ability of each to make changes to the schema of that database. Meetings are required to agree on changes, and release-schedules potentially need to be synchronized. This brings back exactly the issues that STOSA tries to resolve.
Having one component write into another’s database is worse; enforcing data consistency rules then becomes very difficult. See the Integration Database anti-pattern for more info.
Separating databases means that performance issues in one component (eg missing indices on a relational table) cannot affect the performance of a different component.
And partitioning data across multiple databases increases security; a vulnerability in one component only exposes the data that that particular component has available — which is hopefully a small subset of the full dataset.
Synchronous Calls vs Replication
One problem that separation of databases brings is the need to access data owned by a different component/domain. There are two general solutions to this:
- use synchronous calls between domains to obtain data as needed
- replicate data asynchronously
Both solutions are widely used by various companies — though the first is probably more common than the second. And each approach has its advantages and disadvantages.
Systems based on synchronous calls between “microservices”:
- are obvious to build (developers are familiar with such calls)
- don’t need to deal with eventual consistency issues
- have efficient data storage (each data item is stored only once)
- can support very fine-grained microservices (due to point above about storage)
However such systems also:
- can have complex nets of synchronous calls which make it hard to understand dependencies
- need to put lots of effort into interface compatibility
- have complicated failure-modes
- are IO-intensive
- can have performance issues (“chatty APIs”)
- have more potential security issues (each API can be abused, simple firewalling cannot be used between services)
- are difficult to scale appropriately
- can have startup ordering problems
- can lead to development being “blocked” by missing APIs (one tribe’s work requires a new API from another tribe)
- really need distributed-tracing support
- are difficult to test (testing requires interactions with other systems)
The “replication” approach has additional up-front complexity but resolves many of the above problems. Given the (relatively high) volume of traffic that willhaben carries, our relatively small number of back-end developers (50-ish), and our intention to be in business long-term, we are therefore currently applying the “replication” approach — ie we use Distributed Read Models. This approach does require relatively coarse-grained services - but as long as each service belongs exclusively to a single team, we’re happy with that.
Passing Data In
In some cases, an API which depends upon access to read-only “reference” data can require the caller to provide that. Having the caller retrieve the data first via a synchronous call is quite different from having the called service make the same call because the caller is in a distinctly “higher layer”, ie is not a “business service”. It might be the end client itself (mobile app, desktop app, web-browser, or web-presentation-tier), or might be some “integration/aggregation” component that sits in a layer between clients and business services, but in all cases that component can potentially call service A to retrieve data before calling service B, providing data from A as part of the request.
When that input data needs to be “trustworthy” then the integration/aggregation components can often be trusted (this is internal code), or the data can be signed by its provider (service A). While this option won’t be discussed further below, it can be very useful for specific use-cases.
Obviously requests shouldn’t become excessively bloated, so there are limits to the amount of data transferred in that way.
While this approach works for some APIs, there are many to which it does not apply - ie a decision between synchronous calls vs replication still needs to be made for the architecture as a whole.
Benefits of Replicated Data
Introduction
To contrast with the “problems” listed above with synchronous-call-based distributed systems, here are the advantages of a system based on data replication.
In particular, these benefits result when there are NO synchronous calls between back-end components.
Simple ordering requirements for full system restart
When component A calls component B during startup, then on a “cold start” of the system it is necessary to remember to start B first, then A. When no such calls occur, then startup is simple: first platform services such as databases (in any order), then back-end components (in any order), then aggregation-layer components (in any order).
By preventing any rest calls between back-end components, we can enforce this “restartability” without “chaos monkeys”, restart-tests, code-reviews, or other time-consuming manual processes.
Maximum system availability during failure of specific components
When some subset of functions of component A fail if component B is not contactable, then the overall reliability/stability of the system is hard to analyse. When no such calls occur then understanding reliability is easy: only “aggregation-layer” components can ever fail due to their dependencies not currently being available. Back-end components have no unusual failure-modes which need to be tested; they require access to their own databases and Kafka, and that’s about it.
This implies that any “read model” must be cached by each domain so that the data is available even on a restart when the source of the data is not currently available.
Ease of Understanding
A system in which each component is truly “standalone” makes the architecture easily understandable for new (and existing) IT staff.
For obvious reasons, a system where the coupling between deployed software components is easily understandable and easily drawn on a diagram is desirable. There will always be dependencies between “layers” — clients call APIs and back-end components call platform services. However keeping other connections to a minimum reduces the overall complexity.
The first two diagrams in this presentation from bank Monzo show an example of what we would prefer to avoid..
Security
Allowing cross-component rest calls increases the “attack surface” of components — they have additional APIs. And these APIs need some kind of security model which is quite different from the model applied to client requests. When these APIs are not present, then security analysis becomes much easier.
Allowing cross-component calls also reduces security vulnerability to lateral movement — the ability of an attacker who controls one component to use that to gain control of other components within the system. If a component makes NO calls to other components, then we can use firewalls (or similar mechanisms) to make life extremely difficult for an attacker. However if even one call to another component is necessary then (a) we cannot use firewalls to block access between these specific components, and (b) it becomes more complex to block calls to other components; the rule is no longer “block everything” but “block everything except …” where the exceptions need to be configured differently for each component.
Minimal API stability Issues
When no cross-component calls exist then the only APIs for which backwards compatibility must be enforced are:
- calls intended to be used by clients (higher tiers)
- schemas of published (asynchronous) messages
High Performance and Predictable Scalability
Because each client request can be served without communicating with any other back-end component, performance is high and predictable.
Scalability is also predictable: find the bottleneck (whether local IO, local CPU, database, etc) and fix that. There is no need to coordinate scaling with the owner of any other component.
Replicated data is also stored locally in a format optimised for the uses of each system. If using a relational store then the data can be denormalised and have appropriate indexes to optimise access for the exact queries needed.
Simplified Testing
When each component requires only its local database(s) then testing becomes relatively easy; no need for a complex development environment which includes running instances of the services that a component interacts with.
Simplified Debugging
When each component’s functionality depends only on its own code-base and the data in its own database then diagnosing issues becomes relatively simple — at least much simpler than when a problem involves interactions with code that belongs to someone else.
Event Notification Consistency
The “publish/subscribe” design pattern is extensible: once a publisher exists, (new) subscribers just need to register themselves with the broker in order to get notifications. The broker has a well-known address and a well-known process for subscriber-registration; all that subscribers need to know is which topics contain what data.
Increased Development Rate
When developing a new feature, if the data needed is already available in the stream that the data owner provides, then implementation does not require any action on the part of the data owner. This eliminates meetings and priority conflicts.
Different Approaches to Data Replication
The most important concept related to data storage is: each piece of data has exactly ONE owner, and only the owner may change that data. That owner is the “source of truth” for that data; other systems may potentially have copies of it, but must never modify that copy.
Assuming that a data owner does wish to notify others of changes to the dataset (create/update/delete some entity), the following solutions are possible:
- Make a synchronous call to each interested party (“push notification”)
- publish a minimal event (perhaps the ID of the changed entity) and expect others to “call back” to obtain data on that entity if they are interested
- publish a change event that holds info on just the change that occurred to the entity, without its full state
- publish a change event to an event store; others can subscribe to changes in the event store and query all past events for a specific entity id
- publish an event containing the full current state of that entity
Option (1) has a number of complexities. What if a called system is slow to respond? What if a called system is not currently available at all? And how do “subscribers” register for callbacks? These are all problems that message-brokers already solve and so this isn’t a very appealing approach.
Option (2) has performance issues: each subscriber receives the event, then makes a call to the owner. It also requires that the data owner provide an API to retrieve that data (complexity), has performance concerns, and (as noted in the security section above) has security implications.
Option (3), ie “event sourcing”, requires each subscriber to understand how to apply each kind of “change event” that can occur. It also means missed messages lead to incorrect replicated state. Event sourcing can be very powerful — but is best used when the event producer and consumer are the same application, or at least are tightly coupled and are released effectively as a single app.5
Option (4), an alternative implementation of event-sourcing, solves the issue related to missed messages, but at the cost that consumers of the data need to integrate with this event-store. It still has the higher publisher/subscriber coupling due to the need to understand each kind of “change event”.
Option (5) is rather inefficient in disk space usage, but otherwise resolves almost all of the issues with other approaches. Most importantly, the Kafka message broker has a powerful feature called “compacted topics” which allows this to be implemented effectively. This is why this is our chosen solution. We also typically use the term “message” rather than “event” to make clear that these are not change-events/domain-events - even though a message does represent “a change in the data”.
Calls to External Services
While we are attempting to eliminate calls between components in the same “layer”, there will occasionally be a need to call third-party services, or legacy services, using traditional synchronous invocation. So why make this distinction between “internal” interactions (replicate async, notify async) and external interactions (blocking call)? Well first, we recommend to indeed follow the same approach used for internal services when possible. Talk to the provider of the external service and see if asynchronous interaction is possible, ie subscribing to data for reads, and sending asynch commands as messages for writes. If this cannot be done, then try to do synchronous calls to the external service from the aggregation layer instead. However if neither approach is possible then synchronous calls must be accepted within the back-end component layer. Such code does require careful implementation and review as it can cause significant performance impact, even leading to outages, if the component being invoked is not available. This problem of course also exists in the aggregation layer, but there (a) such calls are “standard”, and (b) the code is generally simpler — no true business logic is present in that tier.
So in short, while it is sometimes not possible to exclude all interactions with third-parties from the back-end tier, it is worth trying as hard as possible. And interactions with internal code can be done correctly!
Data Replication and Event Driven Architecture
Event-driven Architecture and Reactive Architecture (effectively the same thing as far as I can see) are hot topics at the moment. They certainly are powerful concepts, allowing systems to provide near-real-time data to its users.
What is proposed in this article is not quite an event-driven architecture. It does use asynchronous messaging to distribute data between processes, and these messages can under some circumstances be used to trigger business processes. However the primary purpose of the approach described here is to build a system of independently-maintainable user-facing services which share some underlying datasets while avoiding the issues that come with synchronous calls between services. The messages are intended to carry data for the purposes of synchronisation rather than inform systems about events.
Adding a “cause” field (some kind of event-descriptor) to the messages described in this article may make the messages usable for some additional purposes, but the “deduplication” process described in part 2 of this series will need to be disabled, and the use of Kafka’s compacted topics may also cause “lost events”. In general, if you want a truly real-time responsive architecture then you may need to instead look at alternative approaches (possibly event-sourcing) with their higher costs - in particular, the higher coupling between services which results.
One aspect of reactive systems is that they reduce the number of inter-service synchronous calls. The architecture proposed here contributes to this by eliminating calls needed for “data sharing”. Whether these data-change events, or additional separate domain events, are used to move the system further towards an event-driven/reactive design is a separate issue.
Although this proposal isn’t directly an event-driven/reactive system, the technical benefits of high reliability and scalability which are often ascribed to that design are present in the approach proposed here.
Summary
By isolating our back-end components from each other, and transferring data only via messages in Kafka compacted topics (published by data owners, consumed by components who need that data) or by having necessary data passed in as part of the request, we achieve performance, stability, developability, testability, debuggability, and security.
Implementing this pattern does have a cost, and for smaller companies, or ones with a slower rate of software change, it may not be worth it. For our circumstances (> 50 back-end developers, multiple releases to production per day) the benefits are estimated to greatly outweigh the cost.
This pattern does also assume that each (micro) service has its own database and services are relatively coarse-grained. If you are aiming for fine-grained services (eg Spotify’s 800 services for 600 developers) and for each service to have a private database, then this data-sync approach may be too expensive in terms of data storage. That design probably instead needs to rely on synchronous calls between services to retrieve data when needed - with the associated issues described above. It seems plausible to choose a database per team, with fine-grained services owned by that team sharing a database - a compromise which could support sharing data between teams via data replication rather than synchronous calls. Data duplication would be kept within reason, at the cost of increased coupling - but only between services belonging to a single team. However it isn’t clear what the advantage would be over simply having a few coarse-grained services per team.
Disclaimer: this data-replication approach is relatively new to us. Our first such “data stream” is now about 1 year old, and we currently have 3 such streams with another 2 coming soon. So we can’t claim to have a battle-proven solution — but it’s also not vaporware.
See part 2 for the implementation details.
References and Further Reading
- [video] CodeOpinion: Rest APIs for Microservices? Beware! - discusses issues related to synchronous calls (which the architecture in this article reduces or eliminates)
- [video] CodeOpinion: Event Carried State Transfer
- [video] Neal Ford: Granularity and Communication Tradeoffs in Microservices
- Netflix: How Netflix microservices tackle dataset pub-sub
- Netflix: Delta Data Synchronization and Enrichment Platform - in which netflix creates “distributed read models” driven from low-level database change-data-capture events. Same final result as approach described here, possibly simpler, but with higher inter-service coupling. See also the Netflix dblog project.
- [video] Christian Posta: The hardest part of microservices is your data
- [video] Managing Data in Microservices (2018) - data distribution is discussed from around minute 30, although the whole presentation is interesting
- [video] Jimmy Bogard: Effective Microservice Communication Patterns (2020) - data replication discussed from minute 60
- [video] David Leitner: Rethinking Reactive Architectures (2021) - in particular, see from minute 25.
- [video] Duana Stanley: Core Decisions in Event-Driven Architecture (2019)
- [video] Dave Farley: Reactive Systems - describes well the problems of systems that rely excessively on synchronous calls between services
- [video] Chris Richardson: Solving distributed data problems in a microservice architecture
- Confluent: Data Dichotomy: Rethinking the way we treat data and services
Change History
This article was written by myself while an employee of willhaben, and originally published on Medium (with link from the company website) in February 2023. Minor updates have been made here in June 2023.
Footnotes
-
The integration layer has a vague resemblance to the “integration bus” or “enterprise service bus (ESB)” patterns. However code in here is optional (most service calls bypass this layer), code here is very simple, and it exists only to support “external API users”. ↩
-
At some future time, simple “aggregation” of data could be performed by something like a GraphQL server. ↩
-
Subdomain might be a more appropriate word here, but is longer to write.. ↩
-
See Rethinking Reactive Architectures from minute 21 (data distribution) and minute 33 (event-sourcing) ↩